Mencia, E. L.; F{ (2008). Efficient pairwise multilabel classification for large-scale problems in the legal domain. In Machine Learning and Knowledge Discovery in Databases, 50--65.
eurlexev
mldr.datasets::get.mldr("eurlexev")
Summary
| Instances | 19348 |
|---|---|
| Attributes | 8993 |
| Inputs | 5000 |
| Labels | 3993 |
| Labelsets | 16467 |
| Single labelsets | 14609 |
| Max frequency | 34 |
| Cardinality | 5.3102 |
| Density | 0.0013 |
| Mean IR | 396.636 |
| SCUMBLE | 0.4201 |
| TCS | 26.5186 |
Citation
@incollection{,
title="Efficient pairwise multilabel classification for large-scale problems in the legal domain",
author="Mencia, E. L. and F{"u}rnkranz, J.",
booktitle="Machine Learning and Knowledge Discovery in Databases",
pages="50--65",
year="2008"
}Concurrence plot
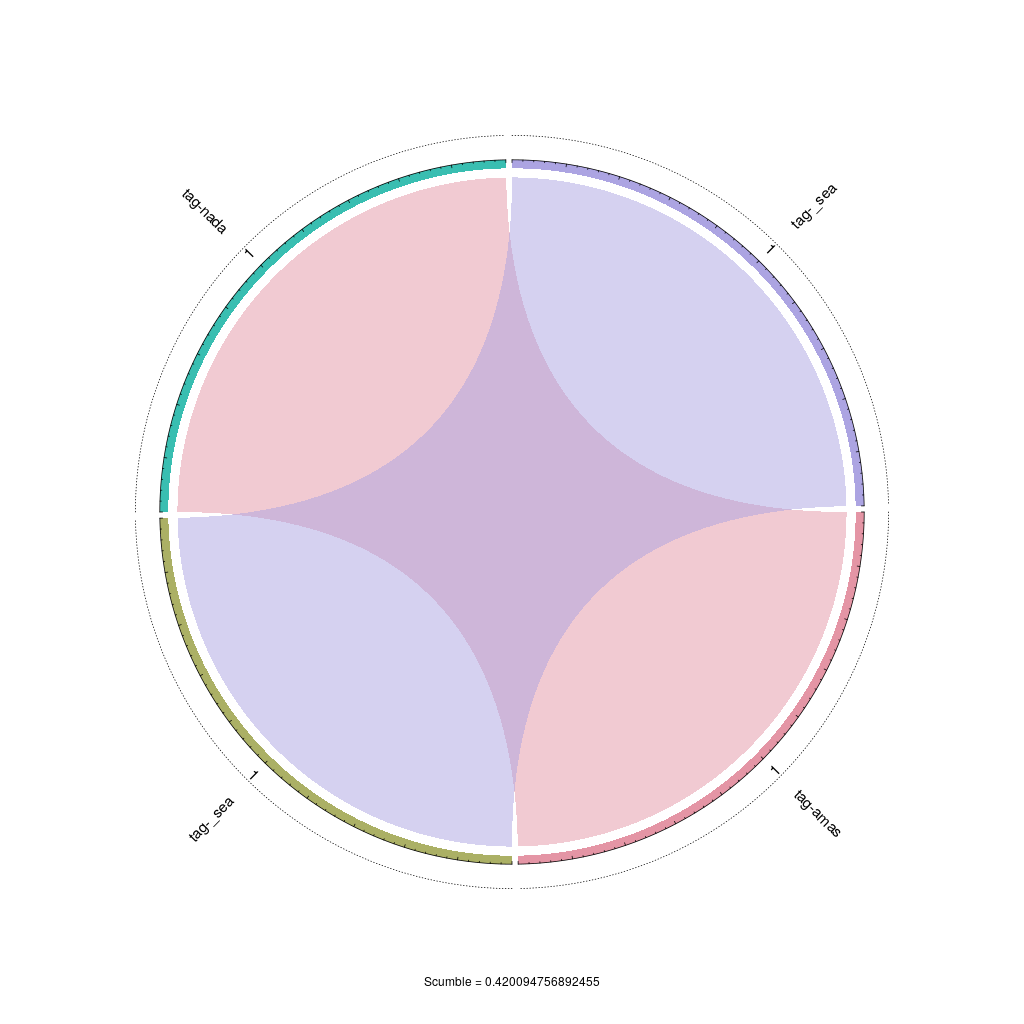
In this concurrence plot, sectors represent labels and links between them depict label co-occurrences. SCUMBLE is a measure designed to assess the concurrence among imbalanced labels.